背景
指导新人在Apache Http Server(httpd) + Axis2/C 搭建的系统中新增调试日志,原计划是利用系统中打印日志的方式打印,但是修改程序后编译失败且评估发现此方案会耗时很多,于是通过创建临时日志文件实现输出来快速满足需求,结果”踩坑”。代码通过精简后如下:
1
2
3
4
5
6
7
8
9
10
11
| #include <stdio.h>
#include <stdlib.h>
...
FILE *fp = fopen("./interface.log", "a+");
if (fp == NULL) {
perror("open file: interface.log failed ");
abort();
}
fprintf(fp, "[DEBUG] Interface: GenerateIndex\n");
fclose(fp);
|
第一次踩坑
添加上述代码后测试,发现interface.log文件没有创建且程序通讯异常,http请求没有响应。于是怀疑创建日志文件没权限导致调用了abort(),执行dmesg 查看日志未发现异常,最后在Apache的error.log中发现如下的日志后确认是文件创建失败。
1
| [core:notice] [pid 7203] AH00052: child pid 19370 exit signal Aborted (6) |
通过在特定目录下创建文件解决权限问题,但是日志文件仍然为空。当时想到文件一般是全缓冲模式,只有填满标准I/O的缓冲区后才进行实际的I/O操作(对于驻留在磁盘的的文件通常是由I/O库实施全缓冲)。
第二次踩坑
于是计划在fprintf(fp, ...)后边新增fflush(fp),为了确认fflush的作用,使用man查询如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| NAME
fflush - flush a stream
SYNOPSIS
#include <stdio.h>
int fflush(FILE *stream);
DESCRIPTION
For output streams, fflush() forces a write of all user-space
buffered data for the given output or update stream via the
stream's underlying write function.
For input streams associated with seekable files (e.g., disk
files, but not pipes or terminals), fflush() discards any buffered
data that has been fetched from the underlying file, but has not
been consumed by the application.
NOTES
Note that fflush() flushes only the user-space buffers provided by
the C library. To ensure that the data is physically stored on
disk the kernel buffers must be flushed too, for example, with
sync(2) or fsync(2).
|
看到NOTES这节,发现fflush()只是将C库提供的用户空间的缓冲区刷新,要想将文件对应的内核缓冲区刷新请调用fsync(),最后是在fprintf(fp, ...)后边新增fsync(fileno(fp)),经过漫长的20分钟编译后测试,还是没有日志输出到interface.log。
解决方案
最后使用fflush() && fsync()解决问题:
1
2
3
4
5
6
7
| int fd = fileno(fp);
fprintf(fp, "[DEBUG] Interface: GenerateIndex\n");
// 想测试Apache是不是会将stderr的信息重定向到原来的日志文件(答案是否定的)
fprintf(stderr, "[DEBUG] Interface: GenerateIndex\n");
fflush(fp);
fsync(fileno(fp));
fclose(fp);
|
反思
事后仔细阅读了fsync()的man手册,并查阅其它资料理解了这两个函数的区别和联系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| NAME
fsync, fdatasync - synchronize a file's in-core state with storage device
SYNOPSIS
#include <unistd.h>
int fsync(int fd);
int fdatasync(int fd);
Feature Test Macro Requirements for glibc (see feature_test_macros(7)):
DESCRIPTION
# fsync 将文件相关的所有更改都刷新到disk device, 这个调用是阻塞的,
# 直到disk通知此函数传输完成。此函数也会将该文件的文件元信息(访问
# 时间或者修改时间等)刷新到磁盘。
fsync() transfers ("flushes") all modified in-core data of (i.e.,
modified buffer cache pages for) the file referred to by the file
descriptor fd to the disk device (or other permanent storage de‐
vice) so that all changed information can be retrieved even if the
system crashes or is rebooted. This includes writing through or
flushing a disk cache if present. The call blocks until the de‐
vice reports that the transfer has completed.
As well as flushing the file data, fsync() also flushes the meta‐
data information associated with the file (see inode(7)).
Calling fsync() does not necessarily ensure that the entry in the
directory containing the file has also reached disk. For that an
explicit fsync() on a file descriptor for the directory is also
needed.
fdatasync() is similar to fsync(), but does not flush modified
metadata unless that metadata is needed in order to allow a subse‐
quent data retrieval to be correctly handled. For example,
changes to st_atime or st_mtime (respectively, time of last access
and time of last modification; see inode(7)) do not require flush‐
ing because they are not necessary for a subsequent data read to
be handled correctly. On the other hand, a change to the file
size (st_size, as made by say ftruncate(2)), would require a meta‐
data flush.
The aim of fdatasync() is to reduce disk activity for applications
that do not require all metadata to be synchronized with the disk.
|
通过上述信息我们可以看出,fsync()需要两次磁盘操作,使用fdatasync()可能减少一次磁盘操作。例如文件数据已经修改,但是文件大小没有变化,则调用fdatasync()只要求更新文件数据。我们知道同步I/O数据完成不要求文件修改时间戳等元数据输出至磁盘。相反,调用fsync()则要求元数据也被传输至磁盘。
对于性能要求很高,或者不需要精确维护某些元数据(如时间戳)的应用来说,按上面的方式减少磁盘I/O操作的数量是很有用的。对于更新许多文件的应用来说,这样做可以获得很大的性能提升,因为文件数据和元数据通常存储在磁盘的不同区域,同时更新二者要求执行2次磁盘定位操作。
总结
fflush() & fsync()区别和联系如下图所示,当时以为直接使用fsync()即可保证将日志信息写入到磁盘文件,但是若文件对应的内核缓冲区中没数据(有可能是数据还没有从C库的缓冲区刷新到内核的文件缓冲区),则依旧没有内容输出到文件。

在经过自己思考过后查阅了蕨菜书的Chapter 13 : File I/O Buffering,发现了其中的一幅图详细和直观的展示了此问题:
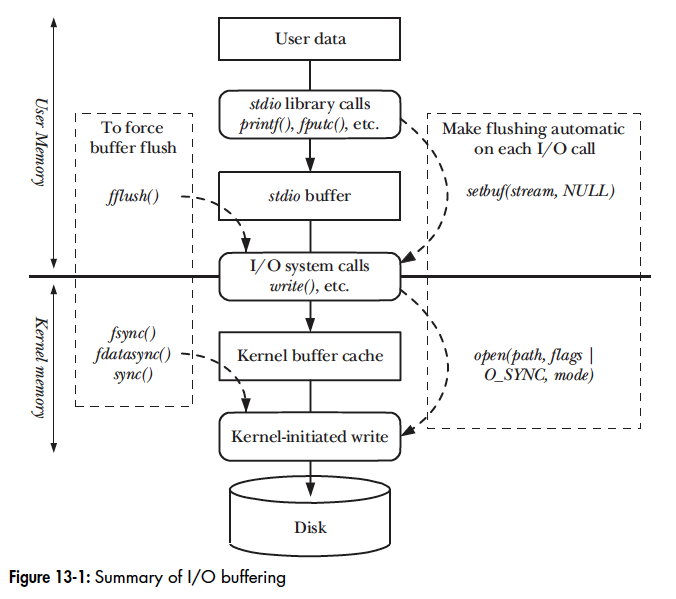
图中综合了stdio库和内核(对于输出文件)采用的缓冲,以及控制缓冲类型的机制。图中间从上到下,我们可以看到stdio库函数把用户数据传输到stdio缓冲区(这些都在用户内存空间中维护)。当这个缓冲区满时,stdio库调用write()系统调用,把数据传输给内核缓冲区缓存(在内核内存中维护)。最后内核发起磁盘操作,将数据传输至磁盘。图的左侧显示了任意时候对缓冲区进行显式强制刷新的调用。右侧则显示了用于自动(隐式)刷新的调用,通过禁止stdio缓冲、或使用同步文件输出系统调用,这样每个write()都立即刷新到磁盘。
后续为了避免此类问题,可以在fprintf(fp, ...)后添加下边两行:
1
2
| fflush(fp);
fsync(fileno(fp));
|
附录
标准I/O提供了三种类型的缓冲:
- 全缓冲。这种情况下,在填满标准I/O缓冲区后才进行实际的I/O操作。对于驻留在磁盘的文件通常由标准I/O库实施全缓冲。
- 行缓冲。在这种情况下,当在输入和输出中遇到换行符时,标准I/O库执行I/O操作。当涉及到一个终端时(例如标准输入和标准输入),通常使用行缓冲。对于行缓冲有个限制,标准库I/O库用来收集每一行的缓冲区的长度是固定的,所以只要填满缓冲区,那么即使还没写入一个换行符,也进行I/O操作。
- 不带缓冲。标准I/O库不对字符进行缓存存储。其中stderr通常是不带缓存的,这样使得错误信息尽可能快的显示。
